
From Image Classification to Multitask Modeling: Building Etsy’s Search by Image Feature

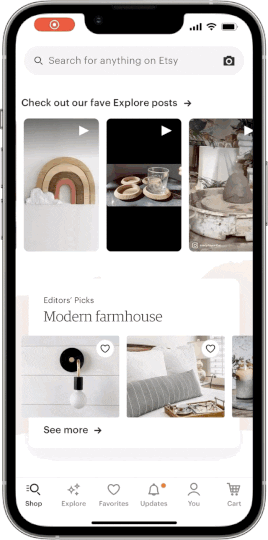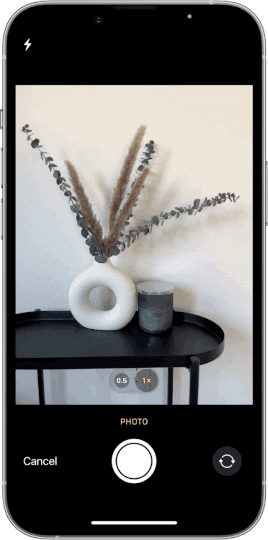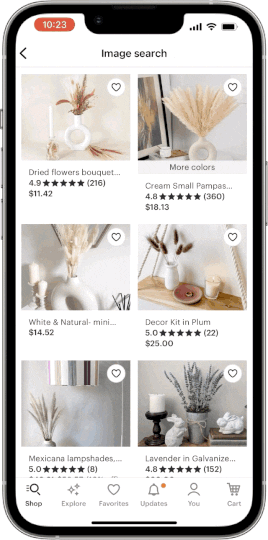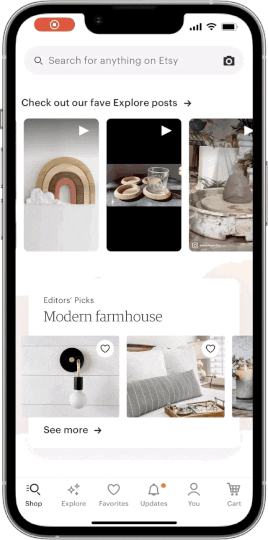
Etsy announced the arrival of a powerful new image-based discovery tool on Etsy’s mobile apps. The ability to search by image gives buyers the opportunity to search the Etsy marketplace using their own photos as a reference. Tap the camera icon in the search bar to take a picture, and in a fraction of a second we’ll surface visually similar results from our inventory of nearly 100 million listings. Searching by image is being rapidly adopted throughout the e-commerce industry, and nowhere does it make more sense than on Etsy, where the uniqueness of our sellers’ creations can’t always be expressed easily with words. In this post we’ll give you a look at the machine-learning architecture behind our search by image feature and the work we did to evolve it.
Overview
In order to search a dataset of images using another image as the query, we first need to convert all those images into a searchable representation. Such a representation is called an embedding, which is a dense vector existing in some relatively low n-dimensional shared space. Once we have the embedding of our query image, and given the precomputed embeddings for our dataset of listing images, we can use any geometric distance metric to look up the closest set of listings to our query. This type of search algorithm is often referred to as a nearest-neighbor search.

At a high level, the visual retrieval system works by using a machine learning model to convert every listing’s image into an embedding. The embeddings are then indexed into an approximate nearest-neighbor (ANN) system which scores a query image for similarity against Etsy's image embeddings in a matter of milliseconds.
Multitask Vision Model
To convert images to embeddings we use a convolutional neural network (CNN) that has been trained on Etsy data. We can break our approach into three components: the model architecture, the learning objective, and the dataset.
Model Architecture
Training the entire CNN from scratch can be costly. It is also unnecessary as the early layers of a pretrained CNN can be shared and reused across new model tasks. We leveraged a pre-trained model and applied transfer learning to fine-tune it on Etsy data. Our approach was to download pre-trained weights into the model and replace the “head” of the model with one for our specific task. During training, we then “freeze” most of the pre-trained weights, and only optimize those for the new classification head as well as for the last few layers of the CNN. The particular pre-trained model we used is called EfficientNet: a family of CNNs that have been tuned in terms of width, depth, and resolution, all to achieve optimal tradeoffs between accuracy and efficiency.
Learning Objective
A proven approach to learning useful embeddings is to train a model on a classification task as a proxy. Then, at prediction time, extracting the penultimate layer just before the classification head produces an embedding instead of a classification probability. Our first attempt at learning image embeddings was to train a model to categorize product images. Not surprisingly, our tests showed that these embeddings were particularly useful in surfacing listings from the same taxonomy. Often though the results were not “visually cohesive”: items were surfaced that didn't match well with the query image in color, material or pattern.
To mitigate this problem we switched to a deep metric learning approach utilizing triplet loss. In this approach, the model is trained on triplets of examples where each triplet consists of an anchor, a positive example, and a negative example. After generating an embedding for each of the three examples, the triplet loss function tries to push the anchor and positive examples closer together, while pushing the negative example farther away. In our case, we used pairs of images from the same item as the anchor and positive examples, and an image from a different listing as the negative example. With these triplet embeddings, tests showed that our listings were now visually cohesive, displaying similar colors and patterns.



But these embeddings lacked categorical accuracy compared to the classification approach. And the training metrics for the triplet approach offered less observability, which made it harder for us to assess the model's learning progress than with classification.

Taxonomy is not something we can tolerate our model being sloppy about. Since classification had already proven its ability to retrieve items of the same type, we decided to see if a multitask classification approach could be made to produce visually consistent results.
Instead of having a single classification head on top of the pre-trained model, we attach separate heads for multiple categorization tasks: Item category (e.g. accessories, home & living), fine-grained item category (belt buckles, dining chairs), primary color, and other item attributes. Loss and training/evaluation metrics are then computed for each task individually while the embedding weights are shared across all of them.
One challenge we faced in implementing this approach was that some optional seller input attributes, such as item color and material, can be sparse. The more tasks we added, the harder it was for us to sample training data equally across classes. To overcome this limitation we implemented a data sampler that reads from entirely disjoint datasets, one for each task, and each with its own unique set of labels. At training time, the sampler combines an equal number of examples from each dataset into every minibatch. All examples then pass through the model, but loss from each classification head is calculated only for examples from the head’s corresponding source dataset.

Returning to the classification paradigm meant that we could once again rely on accuracy metrics as a proxy for gauging and comparing models’ understanding of the domain of each task. This greatly simplifies the process of iterating and improving the model.
Dataset
The embeddings produced by multitask classification were now encapsulating more information about the visual attributes we added tasks for. This meant that when we searched using an embedding of some Etsy listing image, our results were both categorically and visually cohesive.
However, when we talk about search by image, we're not expecting users to search from Etsy listing photos - the whole point of this is that the user is holding a camera. Photos uploaded by sellers are typically high quality, have professional lighting, and are taken over a white or premeditated background. But photos from a user's phone might be blurry, or poorly lit, or on a diversity of backgrounds that distract from the object the user is searching for.
Deep learning is a powerful and useful tool, but training deep learning models is highly susceptible to biases in the data distribution, and training on seller-provided product images was biasing us away from user photos. Fortunately, Etsy allows users to post reviews of items they’ve purchased, and those reviews can have photos attached: photos taken by buyers, often with their phone cameras, very much like the images we expect to see used when searching by image. So we plugged in an additional classification task using the dataset of review photos, expanding the distribution of images our model learns about in training. And indeed with this new component in place we saw significant improvement in the model’s ability to surface visually relevant results.

Inference Pipeline and Serving
Our inference pipeline is an orchestrated ensemble of data processing jobs that turns the entire Etsy inventory of nearly 100M active listings into a searchable framework. We construct an approximate nearest neighbor (ANN) index using an inverted file (IVF) algorithm. The IVF algorithm divides the embedding space into clusters of listings. Later, at query time, we only look at the nearest subset of clusters to the query embedding, which greatly reduces search latency while only marginally impairing accuracy.

While the listing images are indexed in batch offline, the query photo is taken by users on the fly, so we have to infer those in real time - and fast. Due to the size of CNN models, it can take a long time to inference on a CPU. To overcome this hurdle we partnered with Etsy’s ML platform team to bring the first use case of real-time GPU inferencing at Etsy.

We hope this feature gives even more of our buyers a new way to find exactly what they’re looking for on Etsy. So, the next time you come across something you love, snap a photo and search by image on Etsy!
Acknowledgements
This project started as part of CodeMosaic, Etsy’s annual “hackathon” week, where engineers can practice new skills and drive projects not necessarily related to their day-to-day work. We’re proud that we were able to take a proof-of-concept hackathon project, and turn it into a production feature to help make the millions of unique and special items on Etsy more discoverable for buyers. In particular, we’d like to thank the App Core Experience team for taking a chance and prioritizing this project. We could not have done it without the buy-in of leadership and help from our engineering enablement teams. More on this in our next article!


