
Adding Zonal Resiliency to Etsy’s Kafka Cluster: Part 1

In 2018, with its decision to choose Google Cloud Platform as its provider, Etsy began a long project of migration to the cloud. This wasn't just a question of moving out of our data center. Things like on-demand capacity scaling and multi-zone/region resilience don't just magically happen once you’re "in the cloud." To get the full benefits, we undertook a major redesign to host our Kafka brokers (and clients) on Google’s managed Kubernetes (GKE).
Fast forward a few years: we now have many more Kafka clients with streaming applications that power critical user-facing features, like search indexing. Our initial architecture, which saved on cost by operating (mostly) in a single availability zone, was beginning to look shaky. The consequences of a Kafka outage had grown, for example resulting in stale search results. This would have a negative impact on our buyers and sellers alike, and would mean a direct revenue loss to Etsy. We decided it was time to reevaluate.
With some research and thinking, and a good bit of experimentation, we put together a plan to make our Kafka cluster resilient to zonal failures. For such an important production service, the migration had to be accomplished with zero downtime in production. This post will discuss how we accomplished that feat, and where we're looking to optimize costs following a successful rollout.
Single-Zone Kafka
Inter-zone network costs in Google Cloud can add up surprisingly quickly, even exceeding the costs of VMs and storage. Mindful of this, our original design operated the Kafka cluster in one zone only, as illustrated below:
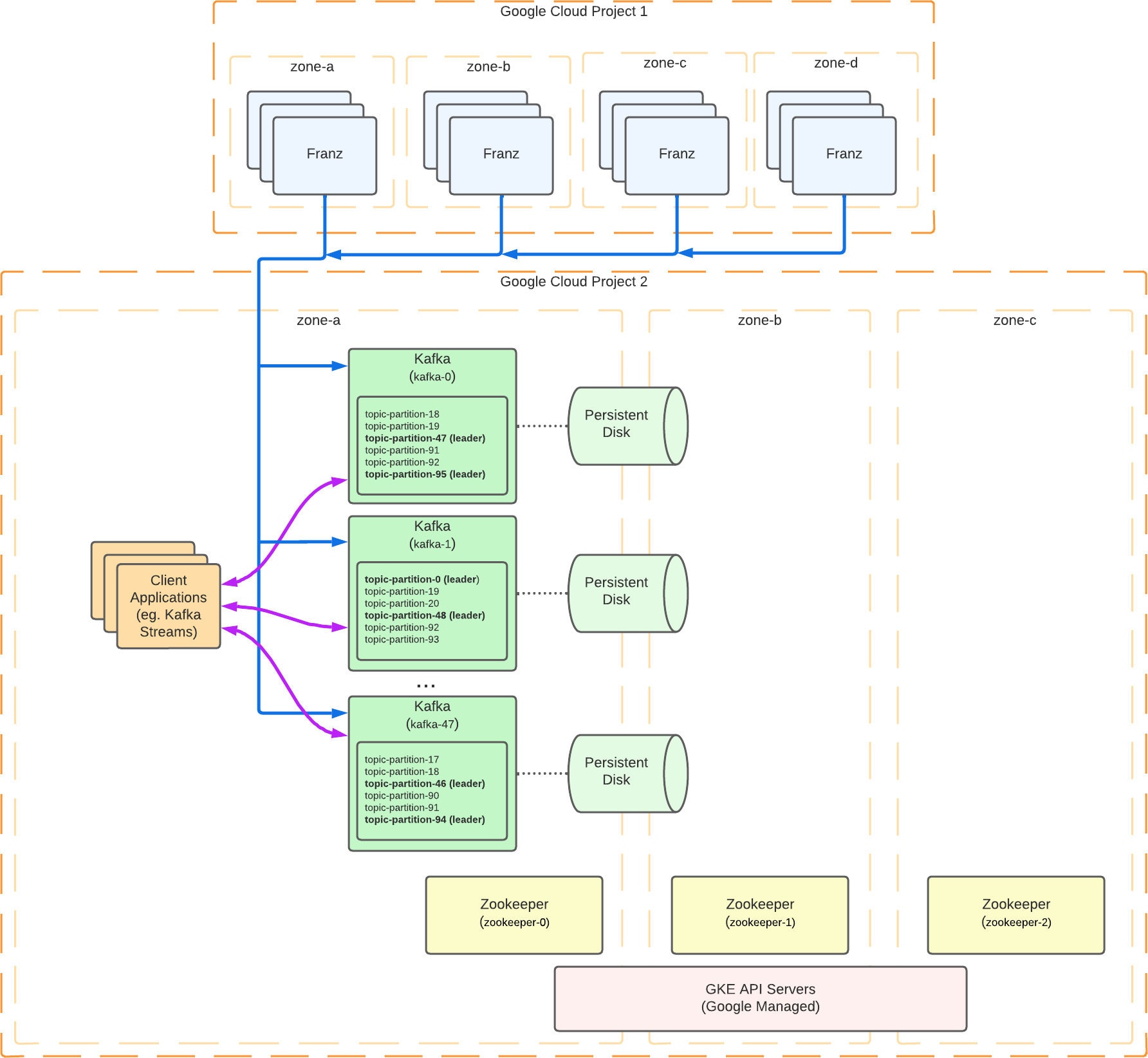
Those with keen eyes might have noticed the Persistent Disks drawn across a zone boundary. This is to indicate that we’re using Google’s Regional PDs, replicated to zones “a” and “b”. (Regular PDs, by contrast, are zonal resources, and can only be accessed from a GCE instance in the same zone.) Even though we weren’t willing to pay the network costs for operating Kafka in multiple zones at the time, we wanted at least some capability to handle Google Cloud zonal outages.
The worst-case scenario in the design above is a “zone-a” outage taking down the entire Kafka cluster. Until the cluster came back up, consumers would be dealing with delayed data, and afterward they'd have to spend time processing the backlog. More concerning is that with the cluster unavailable producers would have nowhere to send their data. Our primary producer, Franz, has an in-memory buffer and unlimited retries as a hedge against the problem, but producer memory buffers aren't unlimited. In the event of a sustained zone outage our runbook documented a plan to have a team member manually relocate the Kafka brokers to zone-b, where disks and historical data have been safely stored. A quick response would be critical to prevent data loss, which might be a lot to ask of a possibly sleepy human.
Multizone Kafka
As Kafka's importance to the business grew–and even though the single-zone architecture hadn’t suffered an outage yet–so did our discomfort with the limitations of manual zone evacuation. So we worked out a design that would give the Kafka cluster zonal resilience:

The most crucial change is that our Kafka brokers are now running in three different zones. The GKE cluster was already regional, so we applied Kubernetes Pod Topology Spread Constraints with topologyKey: topology.kubernetes.io/zone to ensure an even distribution across zones. Less apparent is the fact that topic partition replicas also need to be evenly distributed. We achieve this by setting Kafka’s broker.rack configuration based on the zone where a broker is running. This way, in the event of an outage of any one zone, two out of three partition replicas are still available. With this physical data layout, we no longer need persistent disks to be regional, since Kafka is providing inter-zone replication for us.
Zero-Downtime Migration
Satisfied with the design, we still had the challenge of applying the changes to our production Kafka cluster without data loss, downtime, or negative impact to client applications. The first task was to move broker Pods to their correct zones. Simply applying the Topology Constraints alone resulted in Pods stuck in “Pending” state when they were recreated with the new configs. The problem was that the disks and PVCs for the pods are zonal resources that can only be accessed locally (and even regional disks are limited to just two zones). So we had to move the disks first, then the Pods could follow.
One way to accomplish the move is by actually deleting and recreating the disks. Since we have a replication factor of three on all our topics, this is safe if we do it one disk at a time, and Kafka will re-replicate the missing data onto the blank disk. Testing showed, however, that completing the procedure for all brokers would take an unacceptably long time, on the order of weeks.
Instead, we took advantage of Google’s disk snapshotting feature. Automated with some scripting, the main loop performs roughly the following steps:
- Create a “base” snapshot of the Kafka broker disk, while the broker is still up and running
- Halt the broker:
kubectl delete statefulset --cascade=orphan <kafka-statefulset>kubectl delete pod <kafka-broker-pod>
- Create the “final” snapshot of the same Kafka broker disk, referencing the base snapshot
- Create a brand new disk from the final snapshot, in the correct zone
- Delete the original disk
- Recreate the StatefulSet, which recreates the Pod and starts up the broker
- Wait until the cluster health returns to normal (under replicated partitions is zero)
- Repeat for each broker.
The two-step base/final snapshot process is just an optimisation. The second snapshot is much faster than the first, which minimizes broker downtime, and also reduces the time for partition replication to catch up afterwards.
Now that we’ve got brokers running in the correct zone location, what about partitions? Kafka doesn’t provide automatic partition relocation, and the broker.rack configuration only applies to newly created partitions. So this was a do-it-yourself situation, which at high level involved:
- Generating a list of topic-partitions needing relocation, based on the requirement that replicas need to be distributed evenly across all zones. After some scripting, this list contained 90% of the cluster’s partitions.
- Generating a new partition assignment plan in JSON form. Kafka provides some CLI tools for the job, but we used the SiftScience/kafka-assigner tool instead (with a few of the open PRs applied). This allowed us to minimize the amount of data movement, saving time and reducing load on the cluster.
- Applying partition assignments using the official “kafka-reassign-partitions” CLI tool. To prevent overwhelming the cluster, we throttled the data migration, going in small batches rather than all at once (we had something like 10k partitions to move), and grouping migrations by class of topic, large, small, or empty (with the empty ones probably available for deletion).
It was delicate work that took days of manual effort and babysitting to complete, but the result was a completely successful, zero-downtime partition migration.
Post Migration
In 2021, a company-wide initiative to test and understand zonal resilience in a large number of Etsy's systems, led by Jeremy Tinley, gave us a perfect opportunity to put our multizone Kafka design through its paces. We performed our testing in production, like many other teams (staging environments not being 100% representative), and brought down an entire zone, a third of the Kafka cluster. As leader election and partition replicas became unavailable, client requests automatically switched to still-available brokers, and any impact turned out to be minimal and temporary.
Some napkin math at the time of redesign led us to believe that we would see only minimal cost increases from our multizone setup. In particular, eliminating regional disks (the most expensive Google Cloud SKU in our single-zone design) in favor of Kafka replication would halve our significant storage expense. By current measurements, though, we've ended up with a roughly 20% increase in cost since migration, largely due to higher-than-anticipated inter-zone network costs.
We expected some increase, of course: we wanted an increase, since the whole point of the new architecture is to make data available across zones. Ideally, we would only be traversing zone boundaries for replication, but in practice that ideal is hard to achieve. Kafka's follower fetching feature has helped us make progress on this front. By default, consumers read from the leader replica of a partition, where records are directly produced: but if you're willing to accept some replication latency (well within our application SLOs), follower fetching lets you consume data from same-zone replica partitions, eliminating extra hops across boundaries. The feature is enabled by specifying the client.rack configuration to consumers, and the RackAwareReplicaSelector class for the broker-side replica.selector.class config. This isn’t the only source of inter-zone traffic however, many of our client applications are not pure consumers but also produce data themselves, and when their data is written back to the Kafka cluster across zones. (We also have some consumers in different Google Cloud projects outside our team's control that we haven't been able to update yet.)
Arguably, increased network costs are worth it to be insured against catastrophic zone failures. (Certainly there are some possibly sleepy humans who are glad they won't be called upon to manually evacuate a bad zone.) We think that with continued work we can bring our costs more in line with initial expectations. But even as things stand, the benefits of automatic and fast tolerance to zone outages are significant, and we'll pay for them happily.


