
Towards Machine Learning Observability at Etsy

Etsy has long had comprehensive observability over its machine learning (ML) deployments from a software engineering perspective. Platform-level metrics such as latency, CPU/memory usage, and error rates are readily available on various dashboards for our ML serving platform, Barista. However, for all of the software observability we have in our ML deployments, there’s been no centralized implementation of ML-specific observability. This is a relatively new field, focusing on monitoring the distribution of input features, predictions, and performance metrics.
At its core, ML observability seems simple. It only really “requires” 3 things for comprehensive oversight: input features, a prediction, and a ground truth label. In the search and recommendations space, an example would be trying to predict if a user clicked was going to click on an item. We would log the features (likely user features and features of that item), the prediction our model made (do we predict they’re going to click or not?) and what actually happened (did they actually click on it?).
In practice, processing those things, calculating a variety of metrics with them, and then effectively visualizing, monitoring and alerting on them is an area of active development and few best practices. The scale of the data to process can be massive (terabytes per day for Etsy), and what sounds like simple data logging and plotting actually has a complex set of requirements.
ML observability is just downright hard, even for companies like Etsy who are fortunate enough to have ground truth in most use cases (like search, ads, and recommendations). In this post I want to present our motivations for bringing ML observability to Etsy, the unique challenges we faced, and in the end how we came to our build-versus-buy decision.
Motivations for Implementing Centralized ML Observability
Etsy has some slightly different aims than other organizations I’ve seen when it comes to ML observability. At Etsy, most models are retrained on a 24-hour basis on a sliding window of data (say the last 3 months). Since each day models are updated with the latest data, there’s little chance of poor performance due to model drift - one of the most frequently discussed subtopics of ML observability.
This naive retraining still isn’t very cost-effective, though. As opposed to making an informed decision to retrain our models, based on metrics or other statistics, we’re gratuitously over-training to mitigate the risk of model drift. Through ML observability, we aimed to save on long-term cost by setting up the building blocks that we'd need for future features like intelligent retraining - which would only retrain our large, expensive models as needed.
Lack of observability has also led to more than one production incident with our ML models - models that generate revenue, that we use to connect our sellers with the buyers most likely to want to see them. These incidents had been caused by things like upstream data quality issues in the past, some of which were identified quite late and only solved through tedious, manual debugging.
And so another key goal of building out comprehensive model observability was to reduce the time to remediation of a production incident. If we could more easily identify and troubleshoot issues, we could help ensure silent errors or long-running issues would cause minimal disruption to our customers and Etsy.
Finally, having more insight into feature distributions and model performance would enable ML practitioners to continuously improve our models. This kind of insight would also help in the areas of fairness and bias detection, ensuring our ML serves equitable predictions to all of Etsy's users.
Etsy’s ML Observability Challenges
With objectives in mind, the Machine Learning Infrastructure, Platform and Systems (MIPS) team engaged ML customer teams across Search, Ads, Recs, Computer Vision, and Trust and Safety to source requirements for ML observability. The solution would need to monitor and alert on performance, data quality or drift issues. It should be easy to integrate with, support a variety of metrics spanning different teams (search use cases are very different from computer vision), and offer model explainability out of the box.
We also came up with a number of core requirements ourselves as a platform team. The system should have the scale to handle Etsy’s massive data, be secure enough to protect personal identifying information (PII), and integrate with the complex in-house solutions we work with everyday.
It quickly became clear that what we thought might have a simple implementation would actually need to be exceedingly complex if it were to cover all Etsy use cases. It might be relatively uncomplicated to develop something that suited a single individual or team, but to scale this across Etsy we were talking about a large distributed platform with a lot of moving components. We’d need databases, charts, snappy UIs and graphs, and metrics that spanned almost every field in machine learning. Integration with in-house tools we use for alerting would require further development.
Build versus Buy
At Etsy, we have a wide mix of in-house, open-source, cloud and third-party solutions for different portions of the ML lifecycle. That tends to make third-party tools spanning the entire ML lifecycle a bad fit for us - the more points of integration, the more difficult it is to fit the tool into our existing workflow.
However, as complex as ML observability is - it only has a single point of integration. We were already collecting prediction logs containing the features, prediction, and ground truth for our traffic. We could either build out an entire team to handle the frontend, backend and infrastructure of an in-house tool, or upload this data to a third-party service and get all of these things “for free” without any disruption to our existing ML lifecycle.
ML observability itself is very hard - but it’s not super difficult to slap existing ML observability tooling onto a system that’s already operating and collecting data as it should. This made ML observability an ideal buy decision for our use case, and we sought out vendors that fit our wide range of requirements. Through an extensive POC based on our wide set of requirements, we settled on working with a third-party vendor to handle our observability as a scalable SaaS solution.
High-level ML Observability Design
After procuring our third-party vendor, we began to integrate our prediction logs with the tool. As trivial as I’ve made integration sound thus far, even a single point of integration can prove challenging in complex systems. On our side, the actual act of attributing ground truth to some search, ad, or recommendation is non-trivial and needs to be done at scale. Below is a high-level diagram of a small portion of our feature system that collects prediction logs (called Feature Logs internally) and attributes ground truth (called Attributed Feature Logs).
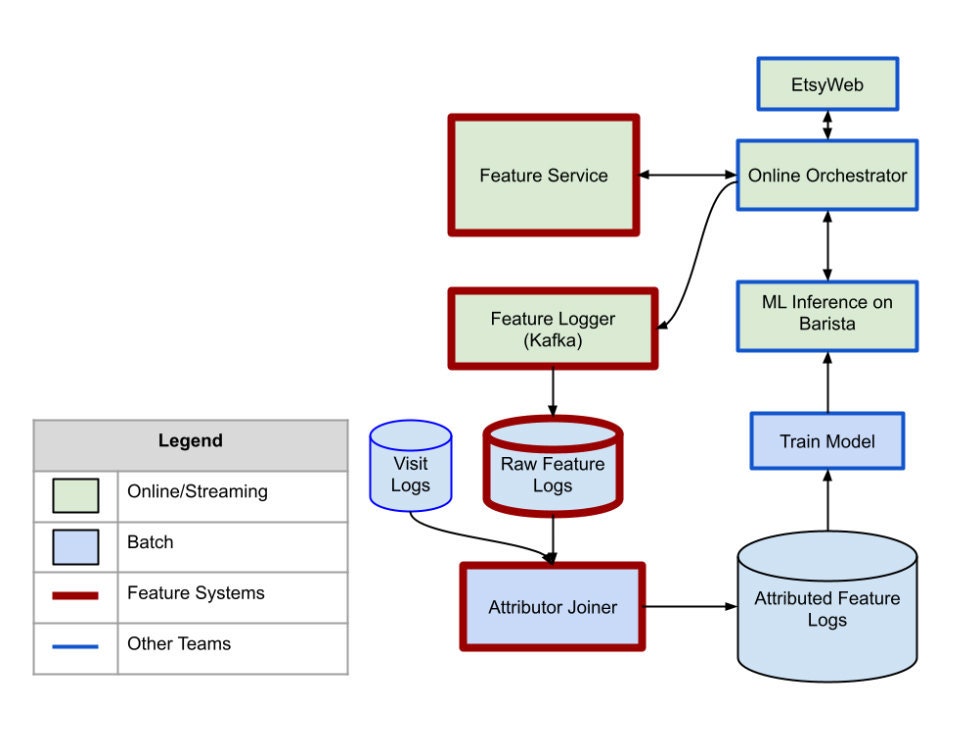
Processing this data to be a good fit for the solution is a challenge in and of itself. Once we’ve stored attributed prediction logs in our Google Cloud Storage buckets (GCS), we need a way to upload them. This requires us to read, preprocess, and push terabytes of data per day. Depending on the use case, we’re currenting using both a custom Kubeflow Pipeline Component (where we push data) and our third-party vendor’s file importer service (which pulls from our buckets directly) to batch upload data directly from attributed data source.
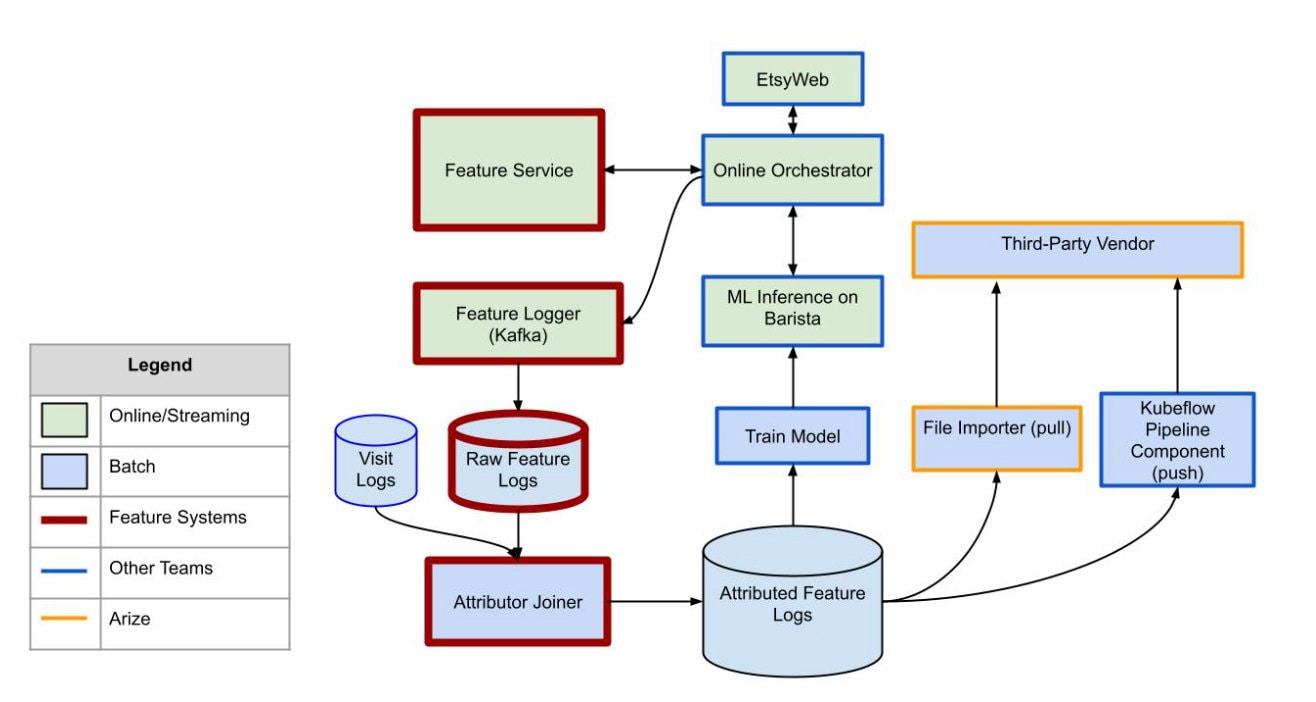
Uploading data using our own Python code lets us carefully control how and what we upload, whereas using the file importer method puts the onus on the third-party vendor to pull data and requires less management on our end.
Obligatory “What’s Next” Section
We’ve only just begun integrating and leveraging all the features of an online ML observability tool at Etsy. As you can see in the diagram above, there are a number of batch processes that are required to generate the data to load in - and nothing yet that’s even near real-time.
However, as we set up monitoring and alerting across our 80+ models in production, we want to start generating value and mitigating previously silent risk for our models serving production traffic. In the long term we can trigger more intelligent model retraining, define robust alerts and write more real-time integrations to further reduce the time to incident remediation.
Special thanks to the massive amount of folks involved with this initiative, including but not limited to Orson Adams, Lucia Yu, Xiaoting Zhao, Mike Morgan, Mason Kirchner, Erica Greene, Mahir Yavuz, Yuqing Pan, Raphael Louca, Han Jiang, Sagar Meisheri, Jerry Soung, Bill Chang, Tanner Whyte, Murium Iqbal, Benjamin Russell, Yogeeta Chatoredussy, Cédric Béliard, Karl Ni, Nicolas Loeff, Kirstin Beal, Kritika Jinagouda, Joe Salem, Tom Metzger, Sallie Walecka, Rob Miles, Mert Sanver, ChuCheng Hsieh and of course our vendor partners.


